Linux Kernel Rebuilding and compilation
Table of contents
Chapter-1
Problem Descriptions 1
1.1 Product perspective 2
1.2 Objective 3
1.3 Scope 5
Chapter-2
Literature Survey 6
2.1 SRS 7
2.2 Feasibility Report 9
2.3 Process model 11
Chapter-3
Module Specification 46
3.1 Module Specification 47
Chapter-4
Coding 58
4.1 Platform used 59
4.1.1 About Linux 59
4.1.2 About Linux kernel 61
4.2 Coding 63
Chapter-5
Testing 67
5.1 kernel testing 68
Chapter-6
Screen Layouts 75
6.1 Screen Layouts 76
Chapter-7
User Manual 91
7.1 Software Requirements 92
7.3 Hardware Requirements 93
7.4 Error Recovery 94
Chapter-8
Conclusion 97
8.1 Conclusion 98
References 101
CHAPTER 1
PROBLEM DESCRIPTION
1.1 PRODUCT PERSPECTIVE
The main reason was once to optimize the kernel to your environment .With modern hardware there is rarely a need to recompile unless there is a particular feature of a new kernel that you must have. The performance gains are probably not noticeable unless specific benchmarks are being run.
The Linux kernel (2.4.x as of this writing) has noticeable improvements for the typical desktop user as a result of the improved scheduling system in the new kernel. Even for older kernels, rebuilding is often necessary for low memory situations, esoteric hardware, and in cases where every ounce of performance must be extracted.
This guide covers the steps necessary to build the 2.4.x series of kernels. Because the process is quite different from one version to the next, the two kernel versions are described in separate chapters.
We describe dependencies between resources, where a resource can be subsystems, modules, procedures, or variable. The dependency relation is quite broad; usually we do not distinguish between function calls, variable reference, and type usage.
The software structure says little about the run-time structure of the Linux kernel. However, we believe that the software structure together with the detailed specifications will give enough information for a potential Linux developer to modify or extend the Linux without reviewing all the source code. We are not mainly concerned with the process view of the Linux kernel because we treat the Linux kernel as one single execution process.
1.2 OBJECTIVE
The main objective of The Linux Kernel Rebuilder is to provide a user defined environment to user. The current era of Microsoft does not provide the core level security to users. Even than the Linux operating system provides the independency.
The security is the main objective of our project. This project provide a core level security and independency by creating own kernel.
USB is designed and implemented in order to access hardware from a simple user application. The driver supports USB bus architecture, protocol and device. It has been tested with USB device (ST72 USB low-speed microcontroller device from ST7 family produced by STMicroelectronics). Driver development is very time-consuming and requires a firm understanding of the basics of operating system internals and driver development. Therefore, this report will briefly discuss both the operating system internals and the driver development (both in user-mode and kernel-mode environment). In order to develop an USB driver, the developer has to have an understanding of USB specification. This report will also briefly discuss the USB specification. The application supports the file operation and the device configuration report. It is believed that it will not be difficult to make it into a GUI application. Both the driver and application is developed and executed successfully in Windows XP PC.
It is common that software development work is usually done in application level (user mode), where the programmer does not have the right to access directly to the hardware in protected operating systems such as Windows, Linux and Solaris. However, there is a solution. By utilizing software modules called device drivers that are located within the operating system (kernel mode), the application can “directly” access the hardware. The application is written and compiled using 32-bit compiler Microsoft Visual Studio .Net. The driver is built in DDK (Driver Development Kit from Microsoft). Both the driver and application code is written in C language. Both the development
machine (for software development) and the user machine (for normal hardware access) run on Windows XP.
The goal of this paper is to present the abstract architecture of the Linux kernel. This is described by Soni as being the conceptual architecture. By concentrating on high-level design, this architecture is useful to entry-level developers that need to see the high level architecture before understanding where their changes fit in. In addition, the conceptual architecture is a good way to create a formal system vocabulary that is shared by experienced developers and system designers. This architectural description may not perfectly reflect the actual implementation architecture, but can provide a useful mental model for all developers to share. Ideally, the conceptual architecture should be created before the system is implemented, and should be updated to be an ongoing system conscience in the sense of showing clearly the load-bearing walls as described in
This presentation is somewhat unusual, in that the conceptual architecture is usually formed before the as-built architecture is complete. Since the author of this paper was not involved in either the design or implementation of the Linux system, this paper is the result of reverse engineering the Slackware 2.0.27 kernel source and documentation. A few architectural descriptions were used (in particular, [Rusling 1997] and were quite helpful, but these descriptions were also based on the existing system implementation. By deriving the conceptual architecture from an existing implementation, this paper probably presents some implementation details as conceptual architecture.
The operating system we do the software development and testing is Windows XP. An operating system is “intuitively” considered a collection of drivers for whatever hardware the end user chooses to populate the system with from one moment to the next. The Windows Driver Model (WDM) provides a framework for drivers that operate in the operating system. Under Windows, software code runs either in user mode (untrusted and restricted to authorized activities only) or in KERNEL mode (fully trusted and able to do anything).
1.3 SCOPE
Linux is a phenomenon of the Internet. Born out of the hobby project of a student it has grown to become more popular than any other freely available operating system. To many Linux is an enigma. How can something that is free be worthwhile? In a world dominated by a handful of large software corporations, how can something that has been written by a bunch of ``hackers'' (sic) hope to compete? How can software contributed to by many different people in many different countries around the world have a hope of being stable and effective? Yet stable and effective it is and compete it does. Many Universities and research establishments use it for their everyday computing needs. People are running it on their home PCs and I would wager that most companies are using it somewhere even if they do not always realize that they do. Linux is used to browse the web, host web sites, write theses, send electronic mail and, as always with computers, to play games. Linux is emphatically not a toy; it is a fully developed and professionally written operating system used by enthusiasts all over the world.
The majority of Linux users do not look at how the operating system works, how it fits together. This is a shame because looking at Linux is a very good way to learn more about how an operating system functions. Not only is it well written, all the sources are freely available for you to look at. This is because although the authors retain the copyrights to their software, they allow the sources to be freely redistributable under the Free Software Foundation's GNU Public License. At first glance though, the sources can be confusing; you will see directories called kernel, mm and net but what do they contain and how does that code work? What is needed is a broader understanding of the overall structure and aims of Linux. This, in short, is the aim of this book: to promote a clear understanding of how Linux, the operating system, works.
CHAPTER 2
LITERATURE SURVEY
2.1 SRS
OVERVIEW
In this report, we used the opportunistic strategy to develop the concrete architecture of the Linux kernel. We used a modified version of the hybrid approach of [Tzerpos 1996] to determine the structure of the Linux kernel. The steps, which are not necessarily in sequential order, are:
• Define Conceptual Architecture. Since we have no direct access to "live" information from the developers, we used our modern operating system domain knowledge to create the Conceptual Architecture of the Linux kernel. This step was done in
• Extract facts from source code. We used the Portable Bookshelf's C Fact Extractor (cfx) and Fact Base Generator (fbgen) to extract dependency facts from the source code.
• Cluster into subsystems. We used the Fact Manipulator (i.e., grok and grok scripts) to cluster facts into subsystems. This clustering was performed partially by the tool (using file names and directories), and partially using our conceptual model of the Linux kernel.
Review the generated software structure. We used the Landscape Layouter, Adjuster, Editor and Viewer to visualize the extracted design information. Based on these diagrams, we could visually see the dependencies between the subsystems. The landscape diagrams confirmed our understanding of the concrete architecture. In cases where the extracted architecture disagreed with the conceptual architecture, we inspected the source code and documentation manually.
Refine clustering using Conceptual Architecture. We used the Conceptual Architecture of the Linux kernel to verify the clustering of the components and the dependencies of these components. Refine layout using Conceptual Architecture. In conjunction with the previous step, we drew the layout of the Linux kernel structure manually using Visio drawing tool.
PRODUCT FUNCTION
There are many views of the Linux kernel, depending on the motive and viewpoint. In this report, we described the concrete architecture using a software structure ([Mancoridis Slides]). We used the software structure to do the following:
• specify the decomposition of the Linux kernel into five major subsystems
• describe the interfaces of the components (i.e., subsystems and modules)
• describe the dependencies between components.
We describe dependencies between resources, where a resources can be subsystems, modules, procedures, or variable. The dependency relation is quite broad; usually we do not distinguish between function calls, variable reference, and type usage.
The software structure says little about the run-time structure of the Linux kernel. However, we believe that the software structure together with the detailed specifications will give enough information for a potential Linux developer to modify or extend the Linux without reviewing all the source code. We are not mainly concerned with the process view of the Linux kernel because we treat the Linux kernel as one single execution process.
2.2 FEASIBILITY REPORT
Software Requirements
The minimum software versions for a kernel build are found in the / Documentation / Changes file of the installed sources. They are as follows- 2.4 x series 2.6.X series
o GnuC 2.95.3 # gcc -version
o Gnu make 3.78 make -version
o binutils 2.12 # Id -v
o util-linux 2.10 #fdformat version
o module-init-tools 0.9.10 # depmod -V
o e2fsprogs 1.29 # tune2fs
o jfsutils 1.1.3 # fsck.jfs -V
o reiserfsprogs 3.6.3 #reiserfsck -V 2>&l|grep reiserfsprogs
o xfsprogs 2.1.0 # xfs_db -V
o pcmda-cs 3.1.21 # cardmgr -V
o quota-tools 3.09 # quota -V
o PPP 2.4.0 # pppd –version
o isdn4k-utils 3.1prel # jsdnctrl 2>8d|grep version
o nfs-utils 1.0.5 # showmount -version
o procps 3.1.13 # ps –version
o oprofile 0.5.3 # oprofiled -version
A common sticking point on distributions transitioning between 2 4 x and 2 6 x kernels is the module-init-tools package which must be updated to work with the 2.6 x kernel. Also, be aware that the underlying version of glibc, the GNU libc package, is implied. If you are upgrading from particularly old distributions then you will likely need to upgrade glibc itself.
Hardware Requirements
Hardware requirements can differ greatly between kernel versions, and indeed. within versions depending upon the configuration. Though the Linux 2.4.x kernel can boot with as little as 8M of RAM. A more realistic number is about 64M. As of this writing, the published minimum hardware required for the typical distribution is about 128M RAM, 2G of hard drive space, and 200 MHz Pentium or equivalent CPU. To actually build the kernel, however, requires a little extra hardware. The kernel sources themselves will occupy anywhere from 40M to 80M of filesystem space. To build them requires a minimum of 400M of drive space for all the interim files. The actual kernel and included modules will require anywhere from 4M for an almost useless, bare minimum kernel to about 40M fully loaded. Luckily, the kernel does not need to be built on the same machine on which it will be deployed. This means that you can compile and package your kernel on a more robust machine and then install on the minimal system.
2.3 PROCESS MODEL
KERNEL ARCHITECTURE
System Structure
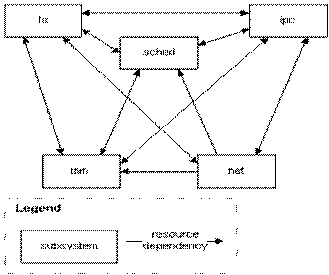
The Linux Kernel is useless by itself; it participates as one layer in the overall system within the kernel layer, Linux is composed of five major subsystems: the process scheduler (sched), the memory manager (mm), the virtual file system (vfs), the network interface (net), and the inter-process communication (ipc). The as-built architecture decomposition is similar to the conceptual architecture decomposition. This correspondence is not too surprising given that the conceptual architecture was derived from the as-built architecture. Our decomposition does not exactly follow the directory structure of the source code, as we believe that this doesn’t perfectly match the subsystem grouping; however, our clustering is quite close to this directory structure.
One difference that became clear after visualizing the extracted design details is that the subsystem dependencies differ quite radically from the conceptual dependencies. The conceptual architecture suggested very few inter-system dependencies, as shown by Figure 1(a). Although the conceptual architecture has few dependencies, the concrete architecture shows that the five major subsystems of the Linux kernel are highly interdependent. Figure 1(b) shows that the connection is only missing two edges from a complete graph gives the details of which modules interact across subsystems). This interdependency is a striking disagreement with the conceptual architecture. It seems that any reverse-engineering technique based on interconnection properties (such as the Rigi system described in would fail to extract any relevant structure from such a system. This validates the hybrid approach discussed by Tzerpos.
The differences at the system level are characteristic of differences at the subsystem level. The subsystem structure corresponds largely to the conceptual structure. However, we found many dependencies in the concrete architecture that weren’t in the conceptual architecture. The reasons for these additional dependencies are discussed in the following section, where we examine the detailed design of each of the major subsystems.
(a): Conceptual Decomposition

(b): Concrete Decomposition
 2.3.1 Subsystem Structure
(A) Process Scheduler
2.3.1 Subsystem Structure
(A) Process Scheduler
Goals
Process scheduling is the heart of the Linux operating system. The process scheduler has the following responsibilities:
• allow processes to create new copies of themselves
• determine which process will have access to the CPU and effect the transfer between running processes
• receive interrupts and route them to the appropriate kernel subsystem
• send signals to user processes
• manage the timer hardware
• clean up process resources when a processes finishes executing
The process scheduler also provides support for dynamically loaded modules; these modules represent kernel functionality that can be loaded after the kernel has started executing. This loadable module functionality is used by the virtual file system and the network interface.
External Interface
The process scheduler provides two interfaces: first, it provides a limited system call interface that user processes may call; secondly, it provides a rich interface to the rest of the kernel system.
Processes can only create other processes by copying the existing process. At boot time, the Linux system has only one running process: init. This process then spawns others, which can also spawn off copies of themselves, through the fork() system call. The fork() call generates a new child process that is a copy of its parent. Upon termination, a user process (implicitly or explicitly) calls the _exit() system call.
Several routines are provided to handle loadable modules. A create_module() system call will allocate enough memory to load a module. The call will initialize the module structure, described below, with the name, size, starting address, and initial status for the allocated module. The init_module() system call loads the module from disk and activates it. Finally, delete_module() unloads a running module.
Timer management can be done through the setitimer() and getitimer() routines. The former sets a timer while the latter gets a timer’s value. Among the most important signal functions is signal(). This routine allows a user process to associate a function handler with a particular signal.
Subsystem Description
The process scheduler subsystem is primarily responsible for the loading, execution, and proper termination of user processes. The scheduling algorithm is called at two different points during the execution of a user process. First, there are system calls that call the scheduler directly, such as sleep(). Second, after every system call, and after every slow system interrupt (described in a moment), the schedule algorithm is called.
Signals can be considered an IPC mechanism, thus are discussed in the inter-process communication section.
Interrupts allow hardware to communicate with the operating system. Linux distinguishes between slow and fast interrupts. A slow interrupt is a typical interrupt. Other interrupts are legal while they are being processed, and once processing has completed on a slow interrupt, Linux conducts business as usual, such as calling the scheduling algorithm. A timer interrupt is exemplary of a slow interrupt. A fast interrupt is one that is used for much less complex tasks, such as processing keyboard input. Other interrupts are disabled as they are being processed, unless explicitly enabled by the fast interrupt handler.
The Linux OS uses a timer interrupt to fire off once every 10ms. Thus, according to our scheduler description given above, task rescheduling should occur at lease once every 10ms.
Data Structures
The structure task_struct represents a Linux task. There is a field that represents the process state; this may have the following values:
• running
• returning from system call
• processing an interrupt routine
• processing a system call
• ready
• waiting
In addition, there is a field that indicates the processes priority, and field which holds the number of clock ticks (10ms intervals) which the process can continue executing without forced rescheduling. There is also a field that holds the error number of the last faulting system call. In order to keep track of all executing processes, a doubly linked list is maintained, (through two fields that point to task_struct). Since every process is related to some other process, there are fields which describe a processes: original parent, parent, youngest child, younger sibling, and finally older sibling. There is a nested structure, mm_struct, which contains a process’s memory management information, (such as start and end address of the code segment). Process ID information is also kept within the task_struct. The process and group id are stored. An array of group id’s is provided so that a process can be associated with more than one group. File specific process data is located in a fs_struct substructure. This will hold a pointer to the inode corresponding to a processors root directory, and it’s current working directory.
All files opened by a process will be kept track of through a files_struct substructure of the task_struct.
Finally, there are fields that hold timing information; for example, the amount of time the process has spent in user mode. All executing processes have an entry in the process table. The process table is implemented as an array of pointers to task structures. The first entry in the process table is the special init process, which is the first process executed by the Linux system.
Subsystem Structure

Process Scheduler Structure
The Process Scheduler subsystem. It is used to represent, collectively, process scheduling and management (i.e. loading and unloading), as well as timer management and module management functionality
Subsystem Dependencies

Process Scheduler Dependencies
The process scheduler depends on other kernel subsystems. The process scheduler requires the memory manager to set up the memory mapping when a process is scheduled. Further, the process scheduler depends on the IPC subsystem for the semaphore queues that are used in bottom-half-handling. Finally, the process scheduler depends on the file system to load loadable modules from the persistent device. All subsystems depend on the process scheduler, since they need to suspend user processes while hardware operations complete. For more details about the specific dependencies between subsystem modules,
(B) Memory Manager
Goals
The memory manager provides the following capabilities to its clients:
• Large address space - user programs can reference more memory than physically exists
• Protection - the memory for a process is private and cannot be read or modified by another process; also, the memory manager prevents processes from overwriting code and read-only-data.
• Memory Mapping - clients can map a file into an area of virtual memory and access the file as memory
• Fair Access to Physical Memory - the memory manager ensures that processes all have fair access to the machine's memory resources, thus ensuring reasonable system performance
• Shared Memory - the memory manager allows processes to share some portion of their memory. For example, executable code is usually shared amongst processes.
External Interface
The memory manager provides two interfaces to its functionality: a system-call interface that is used by user processes, and an interface that is used by other kernel subsystems to accomplish their tasks.
System Call Interface
• malloc() / free() - allocate or free a region of memory for the process's use
• mmap() / munmap() / msync() / mremap() - map files into virtual memory regions
• mprotect - change the protection on a region of virtual memory
• mlock() / mlockall() / munlock() / munlockall() - super-user routines to prevent memory being swapped
• swapon() / swapoff() - super-user routines to add and remove swap files for the system
• Intra-Kernel Interface
• kmalloc() / kfree() - allocate and free memory for use by the kernel’s data structures
• verify_area() - verify that a region of user memory is mapped with required permissions
• get_free_page() / free_page() - allocate and free physical memory pages
In addition to the above interfaces, the memory manager makes all of its data structures and most of its routines available within the kernel. Many kernel modules interface with the memory manager through access to the data structures and implementation details of the subsystem.
Subsystem Description
Since Linux supports several hardware platforms, there is a platform-specific part of the memory manager that abstracts the details of all hardware platforms into one common interface. All access to the hardware memory manager is through this abstract interface.
The memory manager uses the hardware memory manager to map virtual addresses (used by user processes) to physical memory addresses. When a user process accesses a memory location, the hardware memory manager translates this virtual memory address to a physical address, then uses the physical address to perform the access. Because of this mapping, user processes are not aware of what physical address is associated with a particular virtual memory address. This allows the memory manager subsystem to move the process's memory around in physical memory. In addition, this mapping permits two user processes to share physical memory if regions of their virtual memory address space map to the same physical address space.
In addition, the memory manager swaps process memory out to a paging file when it is not in use. This allows the system to execute processes that use more physical memory than is available on the system. The memory manager contains a daemon (kswapd). Linux uses the term daemon to refer to kernel threads; a daemon is scheduled by the process scheduler in the same way that user processes are, but daemons can directly access kernel data structures. Thus, the concept of a daemon is closer to a thread than a process.
The kswapd daemon periodically checks to see if there are any physical memory pages that haven't been referenced recently. These pages are evicted from physical memory; if necessary, they are stored on disk. The memory manager subsystem takes special care to minimize the amount of disk activity that is required. The memory manager avoids writing pages to disk if they could be retrieved another way.
The hardware memory manager detects when a user process accesses a memory address that is not currently mapped to a physical memory location. The hardware memory manager notifies the Linux kernel of this page fault, and it is up to the memory manager subsystem to resolve the fault. There are two possibilities: either the page is currently swapped out to disk, and must be swapped back in, or else the user process is making an invalid reference to a memory address outside of its mapped memory. The hardware memory manager also detects invalid references to memory addresses, such as writing to executable code or executing data. These references also result in page faults that are reported to the memory manager subsystem. If the memory manager detects an invalid memory access, it notifies the user process with a signal; if the process doesn't handle this signal, it is terminated.
Data Structures
The following data structures are architecturally relevant:
• vm_area - the memory manager stores a data structure with each process that records what regions of virtual memory are mapped to which physical pages. This data structure also stores a set of function pointers that allow it to perform actions on a particular region of the process's virtual memory. For example, the executable code region of the process does not need to be swapped to the system paging file since it can use the executable file as a backing store. When regions of a process's virtual memory are mapped (for example when an executable is loaded), a vm_area_struct is set up for each contiguous region in the virtual address space. Since speed is critical when looking up a vm_area_struct for a page fault, the structures are stored in an AVL tree.
• mem_map - the memory manager maintains a data structure for each page of physical memory on a system. This data structure contains flags that indicate the status of the page (for example, whether it is currently in use). All page data structures are available in a vector (mem_map), which is initialized at kernel boot time. As page status changes, the attributes in this data structure are updated.
• free_area - the free_area vector is used to store unallocated physical memory pages; pages are removed from the free_area when allocated, and returned when freed. The Buddy system is used when allocating pages from the free_area.
Subsystem Structure

Memory Manager Structure
The memory manager subsystem is composed of several source code modules; these can be decomposed by areas of responsibility into the following groups
• System Call Interface - this group of modules is responsible for presenting the services of the memory manager to user processes through a well-defined interface (discussed earlier).
• Memory-Mapped Files (mmap) - this group of modules is responsible for supported memory-mapped file I/O.
• Swapfile Access (swap) - this group of modules controls memory swapping. These modules initiate page-in and page-out operations.
• Core Memory Manager (core) - these modules are responsible for the core memory manager functionality that is used by other kernel subsystems.
• Architecture Specific Modules- these modules provide a common interface to all supported hardware platforms. These modules execute commands to change the hardware MMU's virtual memory map, and provide a common means of notifying the rest of the memory-manager subsystem when a page fault occurs.
One interesting aspect of the memory manager structure is the use of kswapd, a daemon that determines which pages of memory should be swapped out. kswapd executes as a kernel thread, and periodically scans the physical pages in use to see if any are candidates to be swapped. This daemon executes concurrently with the rest of the memory manager subsystem.
Subsystem Dependencies

Memory Manager Dependencies
The memory manager is used directly (via data structures and implementation functions) by each of sched, fs, ipc, and net. This dependency is difficult to describe succinctly; please refer to for a detailed view of the subsystem dependencies. Figure 5 shows the high-level dependencies between the memory manager and other subsystems. Internal dependencies are elided for clarity.
(C) Virtual File System
Goals
Linux is designed to support many different physical devices. Even for one specific type of device, such as hard drives, there are many interface differences between different hardware vendors. In addition to the physical devices that Linux supports, Linux supports
a number of logical file systems. By supporting many logical file systems, Linux can inter-operate easily with other operating systems. The Linux file system supports the following goals:
• Multiple hardware devices - provide access to many different hardware devices
• Multiple logical file systems - support many different logical file systems
• Multiple executable formats - support several different executable file formats (like a.out, ELF, java)
• Homogeneity - present a common interface to all of the logical file systems and all hardware devices
• Performance - provide high-speed access to files
• Safety - do not lose or corrupt data
• Security - restrict user access to access files; restrict user total file size with quotas
External Interface
The file system provides two levels of interface: a system-call interface that is available to user processes, and an internal interface that is used by other kernel subsystems. The system-call interface deals with files and directories. Operations on files include the usual open/close/read/write/seek/tell that are provided by POSIX compliant systems; operations on directories include readdir/creat/unlink/chmod/stat as usual for POSIX systems.
The interface that the file subsystem supports for other kernel subsystems is much richer. The file subsystem exposes data structures and implementation function for direct manipulation by other kernel subsystems. In particular, two interfaces are exposed to the rest of the kernel -- inodes and files. Other implementation details of the file subsystem are also used by other kernel subsystems, but this use is less common.
Inode Interface:
• create(): create a file in a directory
• lookup(): find a file by name within a directory
• link() / symlink() / unlink() / readlink() / follow_link(): manage file system links
• mkdir() / rmdir(): create or remove sub-directories
• mknod(): create a directory, special file, or regular file
• readpage() / writepage(): read or write a page of physical memory to a backing store
• truncate(): set the length of a file to zero
• permission(): check to see if a user process has permission to execute an operation
• smap(): map a logical file block to a physical device sector
• bmap(): map a logical file block to a physical device block
• rename(): rename a file or directory
In addition to the methods you can call with an inode, the namei() function is provided to allow other kernel subsystems to find the inode associated with a file or directory.
File Interface:
• open() / release(): open or close the file
• read() / write(): read or write to the file
• select(): wait until the file is in a particular state (readable or writeable)
• lseek(): if supported, move to a particular offset in the file
• mmap(): map a region of the file into the virtual memory of a user process
• fsync() / fasync(): synchronize any memory buffers with the physical device
• readdir: read the files that are pointed to by a directory file
• ioctl: set file attributes
• check_media_change: check to see if a removable media has been removed (such as a floppy)
• revalidate: verify that all cached information is valid
Subsystem Description
The file subsystem needs to support many different logical file systems and many different hardware devices. It does this by having two conceptual layers that are easily extended. The device driver layer represents all physical devices with a common interface. The virtual file system layer (VFS) represents all logical file systems with a common interface. The conceptual architecture of the Linux kernel hows how this decomposition is conceptually arranged.
Device Drivers
The device driver layer is responsible for presenting a common interface to all physical devices. The Linux kernel has three types of device driver: character, block, and network. The two types relevant to the file subsystem are character and block devices. Character devices must be accessed sequentially; typical examples are tape drives, modems, and mice. Block devices can be accessed in any order, but can only be read and written to in multiples of the block size.
All device drivers support the file operations interface described earlier. Therefore, each device can be accessed as though it was a file in the file system (this file is referred to as a device special file). Since most of the kernel deals with devices through this file interface, it is relatively easy to add a new device driver by implementing the hardware-specific code to support this abstract file interface. It is important that it is easy to write new device drivers since there is a large number of different hardware devices.
The Linux kernel uses a buffer cache to improve performance when accessing block devices. All access to block devices occurs through a buffer cache subsystem. The buffer cache greatly increases system performance by minimizing reads and writes to hardware devices. Each hardware device has a request queue; when the buffer cache cannot fulfill a request from in-memory buffers, it adds a request to the device’s request queue and sleeps until this request has been satisfied. The buffer cache uses a separate kernel thread, kflushd, to write buffer pages out to the devices and remove them from the cache.
When a device driver needs to satisfy a request, it begins by initiating the operation with the hardware device manipulating the device’s control and status registers (CSR’s). There are three general mechanisms for moving data from the main computer to the peripheral device: polling, direct memory access (DMA), and interrupts. In the polling case, the device driver periodically checks the CSR’s of the peripheral to see if the current request has been completed. If so, the driver initiates the next request and continues. Polling is appropriate for low-speed hardware devices such as floppy drives and modems. Another mechanism for transfer is DMA. In this case, the device driver initiates a DMA transfer between the computer’s main memory and the peripheral. This transfer operates concurrently with the main CPU, and allows the CPU to process other tasks while the operation is continuing. When the DMA operation is complete, the CPU receives an interrupt. Interrupt handling is very common in the Linux kernel, and it is more complicated than the other two approaches.
When a hardware device wants to report a change in condition (mouse button pushed, key pressed) or to report the completion of an operation, it sends an interrupt to the CPU. If interrupts are enabled, the CPU stops executing the current instruction and begins executing the Linux kernel’s interrupt handling code. The kernel finds the appropriate interrupt handler to invoke (each device driver registers handlers for the interrupts the device generates). While an interrupt is being handled, the CPU executes in a special context; other interrupts may be delayed until the interrupt is handled. Because of this restriction, interrupt handlers need to be quite efficient so that other interrupts won’t be lost. Sometimes an interrupt handler cannot complete all required work within the time constraints; in this case, the interrupt handler schedules the remainder of the work in a bottom-half handler. A bottom-half handler is code that will be executed by the scheduler the next time that a system call has been completed. By deferring non-critical work to a bottom half handler, device drivers can reduce interrupt latency and promote concurrency.
In summary, device drivers hide the details of manipulating a peripheral’s CSR’s and the data transfer mechanism for each device. The buffer cache helps improve system performance by attempting to satisfy file system requests from in-memory buffers for block devices.
Logical File Systems
Although it is possible to access physical devices through their device special file, it is more common to access block devices through a logical file system. A logical file system can be mounted at a mount point in the virtual file system. This means that the associated block device contains files and structure information that allow the logical file system to access the device. At any one time, a physical device can only support one logical file system; however, the device can be reformatted to support a different logical file system. At the time of writing, Linux supports fifteen logical file systems; this promotes interoperability with other operating systems.
When a file system is mounted as a subdirectory, all of the directories and files available on the device are made visible as subdirectories of the mount point. Users of the virtual file system do not need to be aware what logical file system is implementing which parts of the directory tree, nor which physical devices are containing those logical file systems. This abstraction provides a great deal of flexibility in both choice of physical devices and logical file systems, and this flexibility is one of the essential factors in the success of the Linux operating system.
To support the virtual file system, Linux uses the concept of inodes. Linux uses an inode to represent a file on a block device. The inode is virtual in the sense that it contains operations that are implemented differently depending both on the logical system and physical system where the file resides. The inode interface makes all files appear the same to other Linux subsystems. The inode is used as a storage location for all of the information related to an open file on disk. The inode stores associated buffers, the total length of the file in blocks, and the mapping between file offsets and device blocks.
Data Structures
The following data structures are architecturally relevant to the file subsystem:
• super_block: each logical file system has an associated superblock that is used to represent it to the rest of the Linux kernel. This superblock contains information about the entire mounted file system -- what blocks are in use, what the block size is, etc. The superblock is similar to inodes in that they behave as a virtual interface to the logical file system.
• inode: an inode is an in-memory data structure that represents all of the information that the kernel needs to know about a file on disk. A single inode might be used by several processes that all have the file open. The inode stores all of the information that the kernel needs to associate with a single file. Accounting, buffering, and memory mapping information are all stored in the inode. Some logical file systems also have an inode structure on disk that maintains this information persistently, but this is distinct from the inode data structure used within the rest of the kernel.
• file: the file structure represents a file that is opened by a particular process. All open files are stored in a doubly-linked list (pointed to by first_file); the file descriptor that is used in POSIX style routines (open, read, write) is the index of a particular open file in this linked list.
Subsystem Structure

File Subsystem Structure
Subsystem Dependencies

File Subsystem Dependencies
shows how the file system is dependent on other kernel subsystems. Again, the file system depends on all other kernel subsystems, and all other kernel subsystems depend on the file subsystem. In particular, the network subsystem depends on the file system because network sockets are presented to user processes as file descriptors. The memory manager depends on the file system to support swapping. The IPC subsystem depends on the file system for implementing pipes and FIFO’s. The process scheduler depends on the file system to load loadable modules.
The file system uses the network interface to support NFS; it uses the memory manager to implement the buffer cache and for a ramdisk device; it uses the IPC subsystem to help support loadable modules, and it uses the process scheduler to put user processes to sleep while hardware requests are completed.
(B) Inter-Process Communication
Goals
The Linux IPC mechanism is provided so that concurrently executing processes have a means to share resources, synchronize and exchange data with one another. Linux implements all forms of IPC between processes executing on the same system through shared resources, kernel data structures, and wait queues.
Linux provides the following forms of IPC:
• Signals – perhaps the oldest form of Unix IPC, signals are asynchronous messages sent to a process.
• Wait queues – provides a mechanism to put processes to sleep while they are waiting for an operation to complete. This mechanism is used by the process scheduler to implement bottom-half handling as described in section 3.3.3.
• File locks – provides a mechanism to allow processes to declare either regions of a file, or the entire file itself, as read-only to all processes except the one which holds the file lock.
• Pipes and Named Pipes – allows connection-oriented, bi-directional data transfer between two processes either by explicitly setting up the pipe connection, or communicating through a named pipe residing in the file-system.
• System V IPC
• Semaphores – an implementation of a classical semaphore model. The model also allows for the creation of arrays of semaphores.
• Message queues – a connectionless data-transfer model. A message is a sequence of bytes, with an associated type. Messages are written to message queues, and messages can be obtained by reading from the message queue, possibly restricting which messages are read in by type.
• Shared memory – a mechanism by which several processes have access to the same region of physical memory.
• Unix Domain sockets – another connection-oriented data-transfer mechanism that provides the same communication model as the INET sockets, discussed in the next section.
External Interface
A signal is a notification sent to a process by the kernel or another process. Signals are sent with the send_sig() function. The signal number is provided as a parameter, as well as the destination process. Processes may register to handle signals by using the signal() function.
File locks are supported directly by the Linux file system. To lock an entire file, the open() system call can be used, or the sys_fcntl() system-call can be used. Locking areas within a file is done through the sys_fcntl() system call.
Pipes are created by using the pipe() system call. The file-systems read() and write() calls are then used to transfer data on the pipe. Named pipes are opened using the open() system-call.
The System V IPC mechanisms have a common interface, which is the ipc() system call. The various IPC operations are specified using parameters to the system call.
The Unix domain socket functionality is also encapsulated by a single system call, socketcall().
Each of the system-calls mentioned above are well documented, and the reader is encouraged to consult the corresponding man-page. The IPC subsystem exposes wait calls to other kernel subsystems. Since wait queues are not used by user processes, they do not have a system-call interface. Wait queues are used in implementing semaphores, pipes, and bottom-half handlers (see section 3.3.3). The procedure add_wait_queue() inserts a task into a wait queue. The procedure remove_wait_queue() removes a task from the wait queue.
Subsystem Description
The following is a brief description of the low-level functioning of each IPC mechanism identified Signals are used to notify a process of an event. A signal has the effect of altering the state of the recipient process, depending on the semantics of the particular signal. The kernel can send signals to any executing process. A user process may only send a signal to a process or process group if it possesses the associated PID or GID. Signals are not handled immediately for dormant processes. Rather, before the scheduler sets a process running in user mode again, it checks if a signal was sent to the process. If so, then the scheduler calls the do_signal() function, which handles the signal appropriately.
Wait queues are simply linked lists of pointers to task structures that correspond to processes that are waiting for a kernel event, such as the conclusion of a DMA transfer. A process can enter itself on the wait queue by either calling the sleep_on() or interruptable_sleep_on() functions. Similarly, the functions wake_up() and wake_up_interruptable() remove the process from the wait queue. Interrupt routines also use wait-queues to avoid race conditions.
Linux allows user process to prevent other processes from access a file. This exclusion can be based on a whole file, or a region of a file. File-locks are used to implement this exclusion. The file-system implementation contains appropriate data fields in it’s data structures to allow the kernel to determine if a lock has been placed on a file, or a region inside a file. In the former case, a lock attempt on a locked file will fail. In the latter case, an attempt to lock a region already locked will fail. In either case, the requesting process is not permitted to access the file since the lock has not been granted by the kernel.
Pipes and named pipes have a similar implementation, as their functionality is almost the same. The creation process is different. However, in either case a file descriptor is returned which refers to the pipe. Upon creation, one page of memory is associated with the opened pipe. This memory is treated like a circular buffer, to which write operations are done atomically. When the buffer is full, the writing processes block. If a read request is made for more data than what is available, the reading processes block. Thus, each pipe has a wait queue associated with it. Processes are added and removed from the queue during the read and writes.
Semaphores are implemented using wait queues, and follow the classical semaphore model. Each semaphore has an associated value. Two operations, up() and down() are implemented on the semaphore. When the value of the semaphore is zero, the process performing the decrement on the semaphore is blocked on the wait queue. Semaphore arrays are simply a contiguous set of semaphores. Each process also maintains a list of semaphore operations it has performed, so that if the process exits prematurely, these operations can be undone.
The message queue is a linear linked-list, to which processes read or write a sequence of bytes. Messages are received in the same order that they are written. Two wait queues are associated with the message queues, one for processes that are writing to a full message queue, and another for serializing the message writes. The actual size of the message is set when the message queue is created.
Shared memory is the fastest form of IPC. This mechanism allows processes to share a region of their memory. Creation of shared memory areas is handled by the memory management system. Shared pages are attached to the user processes virtual memory space by the system call sys_shmat(). A shared page can be removed from the user segment of a process by calling the sys_shmdt() call.
The Unix domain sockets are implemented in a similar fashion to pipes, in the sense that both are based on a circular buffer based on a page of memory. However, sockets provide a separate buffer for each communication direction.
Data Structures
In this section, the important data structures needed to implement the above IPC mechanisms are described.
Signals are implemented through the signal field in the task_struct structure. Each signal is represented by a bit in this field. Thus, the number of signals a version of Linux can support is limited to the number of bits in a word. The field blocked holds the signals that are being blocked by a process.
There is only one data structure associated with the wait queues, the wait_queue structure. These structures contain a pointer to the associated task_struct, and are linked into a list.
File locks have an associated file_lock structure. This structure contains a pointer to a task_struct for the owning process, the file descriptor of the locked file, a wait queue for processes which are waiting for the cancellation of the file lock, and which region of the file is locked. The file_lock structures are linked into a list for each open file.
Pipes, both nameless and named, are represented by a file system inode. This inode stores extra pipe-specific information in the pipe_inode_info structure. This structure contains a wait queue for processes which are blocking on a read or write, a pointer to the page of memory used as the circular buffer for the pipe, the amount of data in the pipe, and the number of processes which are currently reading and writing from/to the pipe.
All system V IPC objects are created in the kernel, and each have associated access permissions. These access permissions are held in the ipc_perm structure. Semaphores are represented with the sem structure, which holds the value of the semaphore and the pid of the process that performed the last operation on the semaphore. Semaphore arrays are represented by the semid_ds structure, which holds the access permissions, the time of the last semaphore operation, a pointer to the first semaphore in the array, and queues on which processes block when performing semaphore operations. The structure sem_undo is used to create a list of semaphore operations performed by a process, so that they can all be undone when the process is killed.
Message queues are based on the msquid_ds structure, which holds management and control information. This structure stores the following fields:
• access permissions
• link fields to implement the message queue (i.e. pointers to msquid_ds)
• times for the last send, receipt and change
• queues on which processes block, as described in the previous section
• the current number of bytes in the queue
• the number of messages
• the size of the queue (in bytes)
• the process number of the last sender
• the process number of the last receiver.
A message itself is stored in the kernel with a msg structure. This structure holds a link field, to implement a link list of messages, the type of message, the address of the message data, and the length of the message.
The shared memory implementation is based on the shmid_ds structure, which, like the msquid_ds structure, holds management and control information. The structure contains access control permissions, last attach, detach and change times, pids of the creator and last process to call an operation for the shared segment, number of processes to which the shared memory region is attached to, the number of pages which make up the shared memory region, and a field for page table entries.
Subsystem Structure

IPC Subsystem Structure
The IPC subsystem resource dependencies. Control flows from the system call layer down into each module. The System V IPC facilities are implemented in the ipc directory of the kernel source. The kernel IPC module refers to IPC facilities implemented within the kernel directory. Similar conventions hold for the File and Net IPC facilities. The System V IPC module is dependant on the Kernel IPC mechanism. In particular, semaphores are implemented with wait queues.
Subsystem Dependencies

IPC Subsystem Dependencies
The resource dependencies between the IPC subsystem and other kernel subsystems. The IPC subsystem depends on the file system for sockets. Sockets use file descriptors, and once they are opened, they are assigned to an inode. Memory management depends on IPC as the page swapping routine calls the IPC subsystem to perform swapping of shared memory. IPC depends on memory management primarily for the allocation of buffers and the implementation of shared memory.
Some IPC mechanisms use timers, which are implemented in the process scheduler subsystem. Process scheduling relies on signals. For these two reasons, the IPC and Process Scheduler modules depend on each other. For more details about the dependencies between the IPC subsystem modules and other kernel subsystems,
(E) Network Interface
Goals
The Linux network system provides network connectivity between machines, and a socket communication model. Two types of socket implementations are provided: BSD sockets and INET sockets. BSD sockets are implemented using INET sockets.
The Linux network system provides two transport protocols with differing communication models and quality of service. These are the unreliable, message-based UDP protocol and the reliable, streamed TCP protocol. These are implemented on top of the IP networking protocol. The INET sockets are implemented on top of both transport protocols and the IP protocol.
Finally, the IP protocol sits on top of the underlying device drivers. Device drivers are provided for three different types of connections: serial line connections (SLIP), parallel line connections (PLIP), and ethernet connections. An address resolution protocol mediates between the IP and ethernet drivers. The address resolver’s role is to translate between the logical IP addresses and the physical ethernet addresses.
External Interface
The network services are used by other subsystems and the user through the socket interface. Sockets are created and manipulated through the socketcall() system call. Data is sent and received using read() and write() calls on the socket file descriptor.
No other network mechanism/functionality is exported from the network sub-system.
Subsystem Description
The BSD socket model is presented to the user processes. The model is that of a connection-oriented, streamed and buffered communication service. The BSD socket is implemented on top of the INET socket model.
The BSD socket model handles tasks similar to that of the VFS, and administers a general data structure for socket connections. The purpose of the BSD socket model is to provide greater portability by abstracting communication details to a common interface. The BSD interface is widely used in modern operating systems such as Unix and Microsoft Windows. The INET socket model manages the actual communication end points for the IP-based protocols TCP and UDP.
Network I/O begins with a read or write to a socket. This invokes a read/write system call, which is handled by a component of the virtual file system, (the chain of read/write calls down the network subsystem layers are symmetric, thus from this point forward, only writes are considered). From there, it is determined that the BSD socket sock_write() is what implements the actual file system write call; thus, it is called. This routine handles administrative details, and control is then passed to inet_write() function. This in-turn calls a transport layer write call (such as tcp_write()).
The transport layer write routines are responsible for splitting the incoming data into transport packets. These routines pass control to the ip_build_header() routine, which builds an ip protocol header to be inserted into the packet to be sent, and then tcp_build_header() is called to build a tcp protocol header. Once this is done, the underlying device drivers are used to actually send the data.
The network system provides two different transport services, each with a different communication model and quality of service. UDP provides a connectionless, unreliable data transmission service. It is responsible for receiving packets from the IP layer, and finding the destination socket to which the packet data should be sent. If the destination socket is not present, an error is reported. Otherwise, if there is sufficient buffer memory, the packet data is entered into a list of packets received for a socket. Any sockets sleeping on a read operation are notified, and awoken.
The TCP transport protocol offers a much more complicated scheme. In addition to handling data transfer between sending and receiving processes, the TCP protocol also performs complicated connection management. TCP sends data up to the socket layer as a stream, rather than as a sequence of packets, and guarantees a reliable transport service.
The IP protocol provides a packet transfer service. Given a packet, and a destination of the packet, the IP communication layer is responsible for the routing of the packet to the correct host. For an outgoing data stream, the IP is responsible for the following:
• partitioning the stream into IP packets
• routing the IP packets to the destination address
• generating a header to be used by the hardware device drivers
• selecting the appropriate network device to send out on
For an incoming packet stream, the IP must do the following:
• check the header for validity
• compare the destination address with the local address and forwarding it along if the packet is not at it’s correct destination
• defragment the IP packet
• send the packets up to the TCP or UDP layer to be further processed.
The ARP (address resolution protocol) is responsible for converting between the IP and the real hardware address. The ARP supports a variety of hardware devices such as ethernet, FDDI, etc. This function is necessary as sockets deal with IP addresses, which cannot be used directly by the underlying hardware devices. Since a neutral addressing scheme is used, the same communication protocols can be implemented across a variety of hardware devices. The network subsystem provides its own device drivers for serial connections, parallel connections, and ethernet connections. An abstract interface to the various hardware devices is provided to hide the differences between communication mediums from the upper layers of the network subsystem.
Data Structures
The BSD socket implementation is represented by the socket structure. It contains a field which identifies the type of socket (streamed or datagram), and the state of the socket (connected or unconnected). A field that holds flags which modify the operation of the socket, and a pointer to a structure that describes the operations that can be performed on the socket are also provided. A pointer to the associated INET socket implementation is provided, as well as a reference to an inode. Each BSD socket is associated with an inode.
The structure sk_buff is used to manage individual communication packets. The buffer points to the socket to which it belongs, contains the time it was last transferred, and link fields so that all packets associated with a given socket can be linked together (in a doubly linked list). The source and destination addresses, header information, and packet data are also contained within the buffer. This structure encapsulates all packets used by the networking system (i.e. tcp packet, udp packets, ip packets, etc.).
The sock structure refers to the INET socket-specific information. The members of this structure include counts of the read and write memory requested by the socket, sequence numbers required by the TCP protocol, flags which can be set to alter the behavior of the socket, buffer management fields, (for example, to maintain a list of all packets received for the given socket), and a wait queue for blocking reads and writes. A pointer to a structure that maintains a list of function pointers that handle protocol-specific routines, the proto structure, is also provided. The proto structure is rather large and complex, but essentially, it provides an abstract interface to the TCP and UDP protocols. The source and destination addresses, and more TCP-specific data fields are provided. TCP uses timers extensively to handle time-outs, etc. thus the sock structure contains data fields pertaining to timer operations, as well as function pointers which are used as callbacks for timer alarms.
Subsystem Structure

Network Subsystem Structure
The General Network contains those modules that provide the highest level interface to user processes. This is essentially the BSD Socket interface, as well as a definition of the protocols supported by the network layer. Included here are the MAC protocols of 802.x, ip, ipx, and AppleTalk.
The Core services correspond to high-level implementation facilities, such as INET sockets, support for firewalls, a common network device driver interface, and facilities for datagram and TCP transport services.
The system call interface interacts with the BSD socket interface. The BSD socket layer provides a general abstraction for socket communication, and this abstraction is implemented using the INET sockets. This is the reason for the dependency between the General Network module and the Core services module.
The Protocol modules contain the code that takes user data and formats them as required by a particular protocol. The protocol layer finally sends the data to the proper hardware device, hence the dependency between the Network Protocols and Network Devices modules. The Network devices module contains high-level device-type specific routines. The actual device drivers reside with the regular device drivers under the directory drivers/net.
Subsystem Dependencies
Network Subsystem Dependencies
The dependencies between the networking subsystem and other subsystems. The network subsystem depends on the Memory Management system for buffers. The File System is used to provide an inode interface to sockets. The file system uses the network system to implement NFS. The network subsystem uses the kerneld daemon, and thus it depends on IPC. The network subsystem uses the Process Scheduler for timer functions and to suspend processes while network transmissions are executed. For more details about the specific dependencies between the network subsystem modules and other kernel subsystems,
CHAPTER 3
MODULE SPECIFICATION
3.1 Module Specification
The main configuration menu will appear. Selecting an item will bring up another window with further options. These in turn can spawn other sub-menus.

Code Maturity Level Options
This option allows configuration of alpha-quality software. It is best to disable this option if the kernel is intended for a stable production system. If you require an experimental feature in the kernel, such as a driver for new hardware, then enable this option but be aware that it "may not meet the normal level of reliability" as tested code.
Loadable Module Support
You will almost certainly want to enable module support. If you will need third-party kernel modules you will also need to enable Set Version Information on All Module Symbols.
Processor Type and Features
This is perhaps the most important option to choose. In the Preparation section we determined our processor type by examining /proc/cpuinfo and we use that information here to select the appropriate processor. Included in this submenu are features such as Low Latency Scheduling which can improve desktop responsiveness, Symmetric Multi-processing Support for machines with multiple CPUs, and High Memory Support for machines with more than 1G of RAM. Laptop users can also benefit from the CPU Frequency Scaling feature.
General Setup
Choices for PCI, ISA, PCMCIA and other architectural support such as Advanced Power Management are found here.
Memory Technology Devices
MTD devices include Compact Flash devices. Some digital cameras will require this support.
Block Devices
The Block Device section contains options for floppy and hard drives, including parallel port devices, tape drives and RAID controllers. Important options include loopback device support, which allows mounting on disk images, and initrd support, which is needed to preload drivers necessary to boot the system.
Multi-Device support (RAID and LVM)
Important for servers, these options include RAID support for combining multiple disks. Note that this option is not needed for certain hardware RAID that function below the operating system level. LVM is a useful subsystem that allows, among other things, dynamic resizing of filesystems.
ATA/IDE/MFM/RLL support.
This section includes options for IDE/ATAPI chipsets, including performance tweaks such as DMA. Most systems will need this support.
Cryptography Support (CryptoAPI)
Useful options include Loopback Crypto Support, which allows encrypted filesystem images to be mounted. Even with full access to the PC, loopback encryption can help safeguard data.
Networking Options
Many choices are available for networking. TCP/IP, IP tunneling, packet filtering, IPv4 and IPv6, routing support and network QoS are among the most useful. If your kernel is intended for a dedicated firewall or router device, then the options here can significantly improve performance. Read the online and kernel documentation.
SCSI Support
SCSI support is needed for not only true SCSI devices, but also for IDE CDR/W drives in SCSI emulation mode. If your root filesystem is mounted on a SCSI disk, then you must build support directly into the kernel and not as a module.
Character Devices
Dozens of options are available here, including support for many serial and parallel devices, hardware sensors (for system monitors), mice, joysticks and DRM. Many of the options can be safely disabled without problem.
File Systems
It is a good idea to build support for your root filesystem directly into the kernel. Though the initrd utilities can get around the chicken-and-egg boot problem, it is generally safer and easier to just build the fs modules directly. Many options can also be safely disabled if you have no use for the feature.
Once all the configuration changes have been made, you can go ahead and save settings. By defaulti, the configuration is placed in the .config file in the topmost directory. Because this file is deleted by make mrproper and is also hidden, it is a good idea to use the Save to Alternate File before exiting. It will prompt for another save location. Enter something outside of the source tree and with a useful name such as kernel-2.4.22-lowlatency.config. Once this is done, exit the configuration menu. You will be prompted to save the configuration again. Select Yes and continue.
The configuration for the 2.4.x kernel is now complete
DNS
Introduction
Domain Name System (DNS) converts the name of a Web site (www.linuxhomenetworking.com) to an IP address (65.115.71.34). This step is important, because the IP address of a Web site's server, not the Web site's name, is used in routing traffic over the Internet. This chapter will explain how to configure your own DNS server to help guide Web surfers to your site.

Introduction to DNS
DNS Domains
Everyone in the world has a first name and a last, or family, name. The same thing is true in the DNS world: A family of Web sites can be loosely described a domain. For example, the domain linuxhomenetworking.com has a number of children, such as www.linuxhomenetworking.com and mail.linuxhomenetworking.com for the Web and mail servers, respectively.
BIND
BIND is an acronym for the Berkeley Internet Name Domain project, which is a group that maintains the DNS-related software suite that runs under Linux. The most well known program in BIND is named, the daemon that responds to DNS queries from remote machines.
DNS Clients
A DNS client doesn't store DNS information; it must always refer to a DNS server to get it. The only DNS configuration file for a DNS client is the /etc/resolv.conf file, which defines the IP address of the DNS server it should use. You shouldn't need to configure any other files. You'll become well acquainted with the /etc/resolv.conf file soon.
Authoritative DNS Servers
Authoritative servers provide the definitive information for your DNS domain, such as the names of servers and Web sites in it. They are the last word in information related to your domain.
How DNS Servers Find Out Your Site Information
There are 13 root authoritative DNS servers (super duper authorities) that all DNS servers query first. These root servers know all the authoritative DNS servers for all the main domains - .com, .net, and the rest. This layer of servers keep track of all the DNS servers that Web site systems administrators have assigned for their sub domains. For example, when you register your domain my-site.com, you are actually inserting a record on the .com DNS servers that point to the authoritative DNS servers you assigned for your domain.
When To Use A DNS Caching Name Server
Most servers don’t ask authoritative servers for DNS directly, they usually ask a caching DNS server to do it on their behalf. These servers, through a process called recursion, sequentially query the authoritative servers at the root, main domain and sub domain levels to get eventually get the specific information requested. The most frequently requested information is then stored (or cached) to reduce the lookup overhead of subsequent queries.
If you want to advertise your Web site www.my-site.com to the rest of the world, then a regular DNS server is what you require. Setting up a caching DNS server is fairly straightforward and works whether or not your ISP provides you with a static or dynamic Internet IP address.
After you set up your caching DNS server, you must configure each of your home network PCs to use it as their DNS server. If your home PCs get their IP addresses using DHCP, then you have to configure your DHCP server to make it aware of the IP address of your new DNS server, so that the DHCP server can advertise the DNS server to its PC clients. Off-the-shelf router/firewall appliances used in most home networks usually can act as both the caching DNS and DHCP server, rendering a separate DNS server is unnecessary.
When To Use A Static DNS Server
If your ISP provides you with a fixed or static IP address, and you want to host your own Web site, then a regular authoritative DNS server would be the way to go. A caching DNS name server is used as a reference only, regular name servers are used as the authoritative source of information for your Web site's domain.
When To Use A Dynamic DNS Server
If your ISP provides your router/firewall with its Internet IP address using DHCP then you must consider "Dynamic DNS".
Keywords In /etc/resolv.conf
Keyword Value
Nameserver IP address of your DNS nameserver. There should be only one entry per "nameserver" keyword. If there is more than one nameserver, you’ll need to have multiple "nameserver" lines.
Domain The local domain name to be used by default. If the server is bigboy.my-web-site.org, then the entry would just be my-web-site.org
Search If you refer to another server just by its name without the domain added on, DNS on your client will append the server name to each domain in this list and do an DNS lookup on each to get the remote servers’ IP address. This is a handy time saving feature to have so that you can refer to servers in the same domain by only their servername without having to specify the domain. The domains in this list must separated by spaces.
Redhat DNS File Locations
File Purpose RegularBIND Location
named.conf Tells the names of the zone files to be used for each of your website domains. /etc
rndc.key
rndc.conf Files used in named authentication /etc
zone files Links all the IP addresses in your domain to their corresponding server /var/named
APACHE WEB-SERVER
The Apache HTTP Server, commonly referred to simply as Apache, is a web server notable for playing a key role in the initial growth of the World Wide Web. Apache was the first viable alternative to the Netscape Communications Corporation web server (currently known as Sun Java System Web Server), and has since evolved to rival other Unix-based web servers in terms of functionality and performance.
It is often said that the project's name was chosen for two reasons: out of respect for the Native American Indian tribe of Apache (Indé), well-known for their endurance and their skills in warfare, and due to the project's roots as a set of patches to the codebase of NCSA HTTPd 1.3 - making it "a patchy" serve although the latter theory is a lucky coincidence.
Apache is developed and maintained by an open community of developers under the auspices of the Apache Software Foundation. The application is available for a wide variety of operating systems, including Unix, FreeBSD, Linux, Solaris, Novell NetWare, Mac OS X, and Microsoft Windows. Released under the Apache License, Apache is characterized as free software and open source software.
Since April 1996 Apache has been the most popular HTTP server on the World Wide Web. However, since November 2005 it has experienced a steady decline of its market share, lost mostly to Microsoft Internet Information Services. As of February 2008 Apache served 50.93% of all websites
Features
Apache supports a variety of features, many implemented as compiled modules which extend the core functionality. These can range from server-side programming language support to authentication schemes. Some common language interfaces support mod_perl, mod_python, Tcl, and PHP. Popular authentication modules include mod_access, mod_auth, and mod_digest. A sample of other features include SSL and TLS support (mod_ssl), a proxy module, a useful URL rewriter (also known as a rewrite engine, implemented under mod_rewrite), custom log files (mod_log_config), and filtering support (mod_include and mod_ext_filter).
Popular compression methods on Apache include the external extension module, mod_gzip, implemented to help with reduction of the size (weight) of web pages served over HTTP. Apache logs can be analyzed through a web browser using free scripts such as AWStats/W3Perl or Visitors.
Virtual hosting allows one Apache installation to serve many different actual websites. For example, one machine, with one Apache installation could simultaneously serve www.example.com, www.test.com, test47.test-server.test.com, etc.
Apache features configurable error messages, DBMS-based authentication databases, and content negotiation. It is also supported by several graphical user interfaces (GUIs) which permit easier, more intuitive configuration of the server.
Usage
Apache is primarily used to serve both static content and dynamic Web pages on the World Wide Web. Many web applications are designed expecting the environment and features that Apache provides.
Apache is the web server component of the popular LAMP web server application stack, alongside MySQL, and the PHP/Perl/Python programming languages.
Apache is redistributed as part of various proprietary software packages including the Oracle Database or the IBM WebSphere application server. Mac OS X integrates Apache as its built-in web server and as support for its WebObjects application server. It is also supported in some way by Borland in the Kylix and Delphi development tools. Apache is included with Novell NetWare 6.5, where it is the default web server.
Apache is used for many other tasks where content needs to be made available in a secure and reliable way. One example is sharing files from a personal computer over the Internet. A user who has Apache installed on their desktop can put arbitrary files in the Apache's document root which can then be shared.
Programmers developing web applications often use a locally installed version of Apache in order to preview and test code as it is being developed.
Microsoft Internet Information Services (IIS) is the main competitor to Apache, trailed by Sun Microsystems' Sun Java System Web Server and a host of other applications such as Zeus Web Server. Some of the biggest web sites in the world are run using Apache. Google's search engine front end is based on a modified version of Apache, named Google Web Server (GWS), Wikimedia projects, including Wikipedia are also run on Apache servers.
CHAPTER 4
CODING
4.1 PLATFORM USED
4.1.1 ABOUT LINUX
In the early 90s, a geek named Linus Torvalds at the University of Helsinki in Finland thought it would be fun to write a Unix kernel from scratch. He called it Linux, and it was cool but pretty much useless without all the utility programs needed to make it a complete operating system. At the same time, Richard Stallman and his pals at the Free Software Foundation were writing a bunch of freeware Unix utilities collectively known as the GNU Project. It was cool but pretty much useless without a-kernel to make it a complete operating system. Fortunately, the two parties decided to collaborate.
News of Linux spread quickly over the Internet, and many other Unix programmers joined the effort to enhance it. What we now know as Linux is a combination of Torvald's Linux kernel, the GNU Project software, and some other nifty software bit and pieces developed by programmers from all around the world. Today Linux is a complete and reliable implementation of the Unix operating system, with the following notable features: 32-bit operation (it uses all the speed and power of your CPU, unlike 16-bit DOS systems),Virtual memory (it can use all of your system's RAM; there's no 640K memory limit).
Full support for X Windows (Unix's standard graphical user interface) TCP/IP networking support (allowing connection to the Internet) GNU software support (including a huge amount of free Unix software from the GNU Project)
Linux was written totally from scratch without using any of the original AT&T UNIX code. (Throughout this site, UNIX refers to the original trademarked UNIX project invented by AT&T. The term Unix is used here as a generic term for other variants of the operating system.)
Because of that (and because the author is a nice guy), Linux is free. You can obtain the source code, modify, sell or give away the software so long as you provide full source code and don't impose any restrictions on what others do with it.

4.1.2 ABOUT LINUX KERNEL
/usr/src
The 'linux' sub−directory holds the Linux kernel sources, header−files and documentation.
/usr/src/RPM
RPM provides a substructure for building RPMs from SRPMs. Organisation of this branch is fairly logical with packages being organised according to a package's architecture.
/usr/src/RPM/BUILD
A temporary store for RPM binary files that are being built from source code.
/usr/src/RPM/RPMS/athlon,
/usr/src/RPM/RPMS/i386,
/usr/src/RPM/RPMS/i486,
/usr/src/RPM/RPMS/i586,
/usr/src/RPM/RPMS/i686,
/usr/src/RPM/RPMS/noarch
These directories contain architecture dependant RPM source files.
/usr/src/RPM/SOURCES
This directory contains the source TAR files, patches, and icon files for software to be packaged.
/usr/src/RPM/SPECS
RPM SPEC files. A SPEC file is a file that contains information as well as scripts that are necessary to build a package.
/usr/src/RPM/SRPMS
Contains the source RPM files which result from a build.
/usr/src/linux
Contains the source code for the Linux kernel.
/usr/src/linux/.config
The last kernel source configuration. This file is normally created through the 'make config', 'makemenuconfig' or 'make xconfig' steps during kernel compilation.
/usr/src/linux/.depend ,
/usr/src/linux/.hdepend
'make dep' checks the dependencies of the selections you made when you created your .config file. It ensures that the required files can be found and it builds a list that is to be used during compilation.
GNU License
/usr/src/linux/CREDITS
A partial credits−file of people that have contributed to the Linux project. It is sorted by name and formatted to allow easy grepping and beautification by scripts. The fields are: name (N), email (E),web−address (W), PGP key ID and fingerprint (P), description (D), and snail−mail address (S).
4.1 CODING
Determine Current Hardware
Once you have determined that your hardware and software meet the minimum requirements for the kernel build, we will need to collect more detailed information about the system. This is needed during the configuration process when we decide which hardware will be supported under our new kernel. Among the information we will gather include: Processor, Drive type and Controller (SCSI, IDE), Ethernet devices, Graphics and Sound Cards, USB HUB.
We start by running the /sbin/lspci utility to print information about our hardware:
$ /sbin/lspci
Next, we must determine our processor type if not known. Some Linux systems contain a /proc filesystem that allows a user to view raw information about the system. If /proc exists you can issue the following command to get CPU information:
$ cat /proc/cpuinfo
Required Packages For Kernel Rebuilding
#rpm –qa|grep binutils
binutils-2.14.90.0.4-26
#rpm –qa|grep kernel
kernel-utils-2.4-8.37
kernel-2.4.21-4.EL
kernel-smp-2.4.21-4.EL
kernel-source-2.4.21-4.EL
kernel-pcmcia-cs-3.1.31-13
#rpm –qa|grep dev86
dev86-0.16.3-8
#rpm –qa|grep make
make-3.79.1-17
#rpm –qa|grep ncurses
curses-5.3-9.3
#rpm –qa|grep gcc
gcc-3.2.3-20
compat-gcc-7.3-2.96.122
gcc-c++-3.2.3-20
compat-gcc-c++-7.3-2.96.122
compat-libstdc++-7.3-2.96.122
compat-glibc-7.x-2.2.4.32.5
#rpm –qa|grep glibc
Glibc-2.3.2-95.3
gibc-utils-2.3.2-95.3
glibc-headers-2.3.2-95.3
glibc-devel-2.3.2-95.3
glibc-kernheaders-2.3.2-95.3
glibc-common-2.3.2-95.3
To Rebuild New Kernel
#cd /usr/src
#ls
Linux-2.4
#cd linux2.4
#ls-*
Makefile
#vi Makefile
VERSION = 2
PATCHLEVEL = 4
SUBLEVEL = 25
EXTRAVERSION = -5.ELkamal
#cp –p configs/kernel-2.4.21-i686.config arch/i386/defconfig
To preserve Old Kernel.
#make mrproper
It will remove unused files and directories of kernel and then create new files and directories for new kernel.
#make oldconfig
It will activate Old Kernel.
#make menuconfig
It will create New Kernel module.
#make dep bzImage
To launch kernel bootable file.
#ls
Vmlinux
System.map
bzImage
#ls –l arch/i386/boot/bzImage
-rw-r--r—
#make-modules 2>errors
To create new modules for New Kernel.
#make module-install
To install all modules for kernel.
#cp –p arch/i386/boot/bzImage /boot/vmlinuz-2.4.21-4.EL_BANSAL
To copy bzImage to new kernel location.
#cp -p system.map /boot/system.map-2.4.21-4.EL_BANSAL
To copy system map file to new kernel location.
#mkinitrd /boot/initrd-2.4.21-4.EL_BANSAL.img 2.4.21-4.EL_BANSAL
To create RAM disk for New Kernel that will be saved on /lib/modules.
#vi /boot/grub/grub.conf
The initial boot disk entry that will be load on boot time.
CHAPTER 5
TESTING
5.1 KERNEL TESTING
Extract and Patch
Once you have retrieved the kernel sources and patches, you will need to extract them and apply the patches. The pristine 2.4.x and 2.6.x sources can be built as a regular, unprivileged user and this is recommended.
We will begin by creating a directory to hold all the source tarballs and patches, then proceed to extract the sources. For these examples we will assume that you have previously downloaded an earlier release of the kernel and will now need to patch to bring it up to the current version.
$ mkdir src
$ cd src
If your Linux sources are in BZIP compressed format (that is, end with a .bz2 extenstion, then use the following command:
$ tar xfvj /path/to/linux-2.6.0-test7.tar.bz2
Otherwise, use the options for GZIP compressed data:
$ tar xfvz /path/to/linux-2.6.0-test7.tar.gz
You should see a list of filenames scroll by as they are being extracted. Verify that the new kernel source directory is created:
$ ls -l
total 4
drwxr-xr-x 18 kwan users 4096 Oct 8 15:24 linux-2.6.0-test7
-rw-r--r-- 1 kwan users 276260 Nov 15 02:05 patch-2.6.0-test8.gz
-rw-r--r-- 1 kwan users 126184 Nov 15 02:07 patch-2.6.0-test9.gz
Next we must apply the patches in order. Patch files are created by the diff program, and can selectively modify one or more files by adding, deleting, or modifying lines in the source code. Because they contain only the differences between files it is usually a lot faster (and better for the Internet in general) if you patch to the current release. (TBF unclear). Appendix TBF shows a typical patch file. Like the kernel sources, the patch files are also compressed.
$ gunzip patch-2.6.0-test8.gz
$ gunzip patch-2.6.0-test9.gz
$ ls -l
-rw-r--r-- 1 kwan users 1072806 Nov 15 02:05 patch-2.6.0-test8
-rw-r--r-- 1 kwan users 486902 Nov 15 02:07 patch-2.6.0-test9
Once the patches are uncompressed we can apply them to the kernel sources. Remember that it is important to apply them in order.
$ cd linux-2.6.0-test7
$ patch -p1 <../patch-2.6.0.test8
$ patch -p1 <../patch-2.6.0.test9
If it is successful you will see messages similar to the following scroll by:
patching file Documentation/filesystems/jfs.txt
patching file Documentation/filesystems/xfs.txt
patching file Documentation/ia64/fsys.txt
patching file Documentation/ide.txt
patching file Documentation/x86_64/boot-options.txt
patching file Makefile
If unsuccessful you will get a warning and be prompted for a file to patch. If this occurs, press Ctrl-C to break out of the patch utility and verify that you are using the correct patch and applying them in the correct order.
Once all the patches are applied you might consider backing up the directory.
$ cd ..
$ mv linux-2.6.0-test7 linux-2.6.0-test9
$ tar cfvj linux-2.6.0-test9.tar.bz2 linux-2.6.0-test9
Recovery From a Failed Compile
The foremost concern of inexperienced software compilers is recovering from an unsuccessful compile. Recovery is a straightforward task if diligent about maintaining consistent file and directory naming conventions. If using the embedded EXTRAVERSION option, this consistency is automated because the extra version number is embedded directly into the software code and file and directory names. If using a manual extra version option, as done in this guideline, then maintaining that same consistency allows for quick recovery.
Consider that regardless of the extra version method used, the following original files exist in /boot:
config-ide-2.4.31
System.map-ide-2.4.31
vmlinuz-ide-2.4.31
After compiling the modified kernel, the following new files exist in /boot:
config-ide-2.4.31-i586-1
System.map-ide-2.4.31-i586-1
vmlinuz-ide-2.4.31-i586-1
If using the embedded EXTRAVERSION method, after compiling the /lib/modules directory contains the following directories:
2.4.31
2.4.31-1
2.4.31-orig
Realize that the 2.4.31 and 2.4.31-orig directories are the same. However, because the EXTRAVERSION number is embedded, the kernel is compiled to use the 2.4.31-1 directory to load modules. This is automated by design. The kernel ignores the 2.4.31 directory.
If using the manual extra version method, after compiling the /lib/modules directory contains the same directories:
2.4.31
2.4.31-1
2.4.31-orig
However, realize with this method the 2.4.31 and 2.4.31-1 directories are the same and both are different from the 2.4.31-orig directory. The kernel was not compiled with the embedded EXTRAVERSION option, so the kernel still loads modules from the 2.4.31 directory.
With either method recovering from a failed compile is straightforward. If using the embedded EXTRAVERSION method there are no backups to restore. Merely use the boot loader option for the previously successful kernel version.
With the manual extra version method, some manual restoration is necessary:
rm -Rf /lib/modules/2.4.31
rm -Rf /lib/modules/2.4.31-1
cp -Rp /lib/modules/2.4.31-orig /lib/modules/2.4.31
Then use the boot loader option for the previously successful kernel version.Because I created a work area to compile the kernel, the original /usr/src/linux-2.4.31 directory remains untouched and is never a concern. With respect to the kernel source code, recovering from a failed compile is as easy as executing a make mrproper and creating a new configuration file. In a worst case scenario, delete all files in /home/builds/kernels/2.4.31 and copy the original /usr/src/linux-2.4.31 files.
Caveat: When copying the updated module files to another computer, be sure not to copy the /lib/modules/2.4.31/build soft link. That target for that link—your work area directory—likely does not exist on other systems.
Final Comments
Probably one of the most frustrating aspects of compiling a kernel is failed module dependencies. As I remarked at the beginning of this guideline, I do not pretend to be an expert on kernel or software compiling. However, a dependency issue means just that—a required module is missing and the reason is the module was not compiled. That is, a feature you selected within the kernel configuration is dependent upon another feature that you did not enable. The best solution is to think and visit the online forums to better understand why the compile process failed with certain modules.
If your first kernel compile succeeded, then likely you will be attempting additional modifications to the kernel and compiling again. If using the embedded EXTRAVERSION option, and not minding recompiling those additional software packages using kernel modules, then updating and preserving previous /lib/modules/2.4.31 directories is always an automated process, as well as being able to use the make install command to install the new kernel to the /boot directory. Using the embedded EXTRAVERSION option does promote a certain ease of use and updating, and all file and directory naming is automated by the Makefile. The one caveat with this approach is recompiling all of those external packages using kernel modules.
A majority of people, however, do not want to recompile those additional packages. They should use the manual version numbering process as used in this guideline. The one caveat with this method is manually backing up previous working modules. Therefore, after each successful compile and reboot, be sure to copy the newly updated /lib/modules/2.4.31 directory to /lib/modules/2.4.31-x, where x represents the new version number being used manually.
Basic DNS Testing of DNS Resolution
As you know, DNS resolution maps a fully qualified domain name (FQDN), such as www.linuxhomenetworking.com, to an IP address. This is also known as a forward lookup. The reverse is also true: By performing a reverse lookup, DNS can determining the fully qualified domain name associated with an IP address.
Many different Web sites can map to a single IP address, but the reverse isn't true; an IP address can map to only one FQDN. This means that forward and reverse entries frequently don't match. The reverse DNS entries are usually the responsibility of the ISP hosting your site, so it is quite common for the reverse lookup to resolve to the ISP's domain. This isn't an important factor for most small sites, but some e-commerce applications require matching entries to operate correctly. You may have to ask your ISP to make a custom DNS change to correct this.
There are a number of commands you can use do these lookups. Linux uses the host command, for example, but Windows uses nslookup.
CHAPTER 6
SCREEN LAYOUTS
LINUX SOURCE CODE DIRECTORY

PACKAGE INFORMATION


NEW VERSION NAME FOR NEW KERNEL

SAVING OLD CONFIGURATION OF KERNEL

LOADABLE KERNEL MODULES

REMOVING USB SUPPORT FOR NEW KERNEL



SAVING NEW CONFIGURATION

COMPILING KERNEL AND LAUNCHING vmlinux

CREATING NEW KERNEL MODULES

CODING FOR GRUB LOADER


DNS SERVER

FORWORD MASTER ZONE

REVERSE MASTER ZONE
CHAPTER 7
USER MANUAL
7.1 Software Requirements
The minimum software versions for a kernel build are found in the / Documentation / Changes file of the installed sources. They are as follows- 2.4 x series 2.6.X series
• GnuC 2.95.3 # gcc -version
• Gnu make 3.78 make -version
• binutils 2.12 # Id -v
• util-linux 2.10o #fdformat version
• module-init-tools 0.9.10 # depmod -V
• e2fsprogs 1.29 # tune2fs
• jfsutils 1.1.3 # fsck.jfs -V
• reiserfsprogs 3.6.3 #reiserfsck -V 2>&l|grep reiserfsprogs
• xfsprogs 2.1.0 # xfs_db -V
• pcmda-cs 3.1.21 # cardmgr -V
• quota-tools 3.09 # quota -V
• PPP 2.4.0 # pppd –version
• isdn4k-utils 3.1prel # jsdnctrl 2>8d|grep version
• nfs-utils 1.0.5 # showmount -version
• procps 3.1.13 # ps –version
• oprofile 0.5.3 # oprofiled -version
A common sticking point on distributions transitioning between 2 4 x and 2 6 x kernels is the module-init-tools package which must be updated to work with the 2.6 x kernel. Also, be aware that the underlying version of glibc, the GNU libc package, is implied. If you are upgrading from particularly old distributions then you will likely need to upgrade glibc itself.
7.2 Hardware Requirements
Hardware requirements can differ greatly between kernel versions, and indeed. within versions depending upon the configuration. Though the Linux 2.4.x kernel can boot with as little as 8M of RAM. a more realistic number is about 64M. As of this writing, the published minimum hardware required for the typical distribution is about 128M RAM, 2G of hard drive space, and 200MhZ Pentium or equivalent CPU. To actually build the kernel, however, requires a little extra hardware. The kernel sources themselves will occupy anywhere from 40M to 80M of filesystem space. To build them requires a minimum of 400M of drive space for all the interim files. The actual kernel and included modules will require anywhere from 4M for an almost useless, bare minimum kernel to about 40M fully loaded. [1] Luckily, the kernel does not need to be built on the same machine on which it will be deployed. This means that you can compile and package your kernel on a more robust machine and then install on the minimal system.
7.3 ERROR RECOVERY AND TROUBLE SHOOTING
Recovery From a Failed Compile
The foremost concern of inexperienced software compilers is recovering from an unsuccessful compile. Recovery is a straightforward task if diligent about maintaining consistent file and directory naming conventions. If using the embedded EXTRAVERSION option, this consistency is automated because the extra version number is embedded directly into the software code and file and directory names. If using a manual extra version option, as done in this guideline, then maintaining that same consistency allows for quick recovery.
Consider that regardless of the extra version method used, the following original files exist in /boot:
config-ide-2.4.31
System.map-ide-2.4.31
vmlinuz-ide-2.4.31
After compiling the modified kernel, the following new files exist in /boot:
config-ide-2.4.31-i586-1
System.map-ide-2.4.31-i586-1
vmlinuz-ide-2.4.31-i586-1
If using the embedded EXTRAVERSION method, after compiling the /lib/modules directory contains the following directories:
2.4.31
2.4.31-1
2.4.31-orig
If using the manual extra version method, after compiling the /lib/modules directory contains the same directories:
2.4.31
2.4.31-1
2.4.31-orig
With either method recovering from a failed compile is straightforward. If using the embedded EXTRAVERSION method there are no backups to restore. Merely use the boot loader option for the previously successful kernel version.
With the manual extra version method, some manual restoration is necessary:
rm -Rf /lib/modules/2.4.31
rm -Rf /lib/modules/2.4.31-1
cp -Rp /lib/modules/2.4.31-orig /lib/modules/2.4.31
Then use the boot loader option for the previously successful kernel version.
Errors
gcc -D__KERNEL__ -I/usr/src/linux-2.4.21/linux/
include -E -traditional -DSVGA_MODE=NORMAL_VGA
bootsect.S -o bootsect.s
as86 -0 -a -o bootsect.o bootsect.s
make[1]:as86: command not found.
make[1]: ***[bootsect.o] error 127
make[1]: Leaving directory '/usr/src/linux-2.2.15/
linux/arch/i386/boot'
make: ***[zImage] error 2.'
This is a sample error message. In this case, as86 was not installed on the system. We rectified the problem by installing the package that contained the missing file.
CHAPTER 8
CONCLUSION
8.1 CONCLUSION
This method of kernel compilation will ensure that not only will you be able to test newer kernels or newer features (or even add some older features) but you will also have a working kernel on your machine. Granted, it's ill-advised to tinker around with the kernel of a production machine (unless you know exactly what you are doing) but the process outlined above will make kernel compilation a whole heck of a lot safer.
Running multiple kernels
You may have noticed, that when installing the sources for your newer kernel, the sources for your existing kernel were not removed. This is by design -- it allows you to easily switch between running different kernels.
Switching between multiple kernels is as simple as leaving the kernel sources under /usr/src/ and leaving the bzImage binaries on your /boot partition (referenced by entries in your boot loader configuration). Every time you boot up, you will be presented with a choice of which kernel to boot into.
ADVANTAGES OF NEW KERNEL
• You can enable optimizations which can make your kernel faster (for example, if you have a PII, you can specifically compile for 'i686' a way which can take advantage of PII's special instruction set and/or capabilities).
• Suddenly, it may become known that a security or other important vulnerability/bug was discovered in your current version of your kernel, which does not leave you other choice but to upgrade your kernel to a version that has fixed the problem.
• To support more specific hardware that your stock kernel does not support by default.
• To take advantage of the new features or driver versions that a newer kernel has to offer.
• To apply specific patches that are not part of the standard kernel feature set, but you feel that you want to toy with.
• To compile the kernel with only the hardware setup of your machine (instead of the full spectrum of support that comes with stock kernels) so your kernel file will be smaller and maybe even faster.
you can install bug-fixes, security updates, or new functionality by rebuilding the kernel from updated sources.
by removing unused device drivers and kernel sub-systems from your configuration, you can dramatically reduce kernel size and, therefore, memory usage.
by enabling optimisations more specific to your hardware, or tuning the system to match your specific sizing and workload, you can improve performance.
you can access additional features by enabling kernel options or sub-systems, some of which are experimental or disabled by default.
you can solve problems of detection/conflicts of peripherals.
you can customize some options (for example keyboard layout, BIOS clock offset, ...)
you can get a deeper knowledge of the system.
With this guide in hand you can now begin your experimentation with the kernel in a reasonably sensible way. Hopefully the threshold to start playing with the kernel is lowered enough that you are eager to get started. Most of your time will be spent deciding on the correct kernel configuration, while during compilation you can safely play 'freecell' or do other computer work.
The new kernel has better hardware support.
• The new kernel offers certain advantages, such as better support for multiple-processor machines (SMP), or support for the USB. NTFS file system support This applies to the 2.4.x kernels.
The new kernel lacks old bugs.
Your own kernel lacks superfluous elements and is therefore faster and more stable.
It is a problem that compiling ("rolling") your own kernel demands a fair amount of computer savvy. Therefore a new Linux user will not attempt to get into compiling kernels lightly. This article shows screen dumps of the way to do compile the kernel using the command 'make xconfig'. With this command the user handles the kernel through a GUI, a Graphical User Interface, and the mouse. There are about 40 screen dumps, which clarify why you do or do not choose certain options in particular situations. Discussing these 40 screen dumps may seem excessive, but it is the best way to clarify the kernel's internal workings and the how and why of certain kernel options. The screen dumps are based on kernel-2.4.6. The newest kernel is now 2.4.19, but apart from a few extra entries in the menus (e.g., support for new hardware) the screen shots are the same and the process of compiling the kernel is too.
REFERENCES
www.sourceforge.net
www.kernel.org
www.redhat.com
www.linux.org
www.linuxhq.com
Linux Kernel Programming By M.Beck
www.kernelnewbies.org



 # vigr
# vigr